
☰
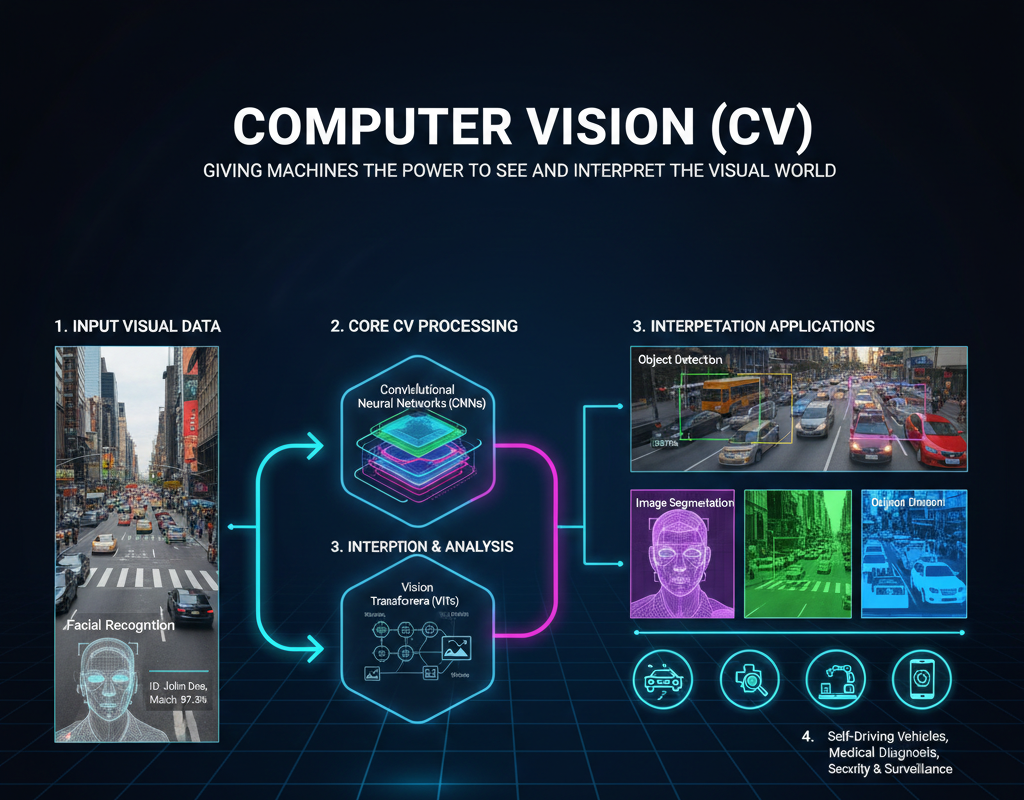
Computer Vision (CV) is a field of artificial intelligence that enables computers and systems to derive meaningful information from digital images, videos, and other visual inputs. Often described as giving "eyes" to machines, CV goes beyond simple recording; it involves complex algorithms that allow software to identify, classify, and interpret objects within a visual scene.
At its core, modern Computer Vision relies heavily on Convolutional Neural Networks (CNNs) and, more recently, Vision Transformers (ViTs). These technologies break down images into pixels to detect patterns, such as edges, textures, and eventually complex shapes. Common tasks include object detection (locating items in a frame), image segmentation (partitioning an image into segments), and facial recognition. Today, Computer Vision is a critical component in self-driving cars, medical imaging diagnostics, and industrial automation, bridging the gap between raw visual data and actionable intelligence.
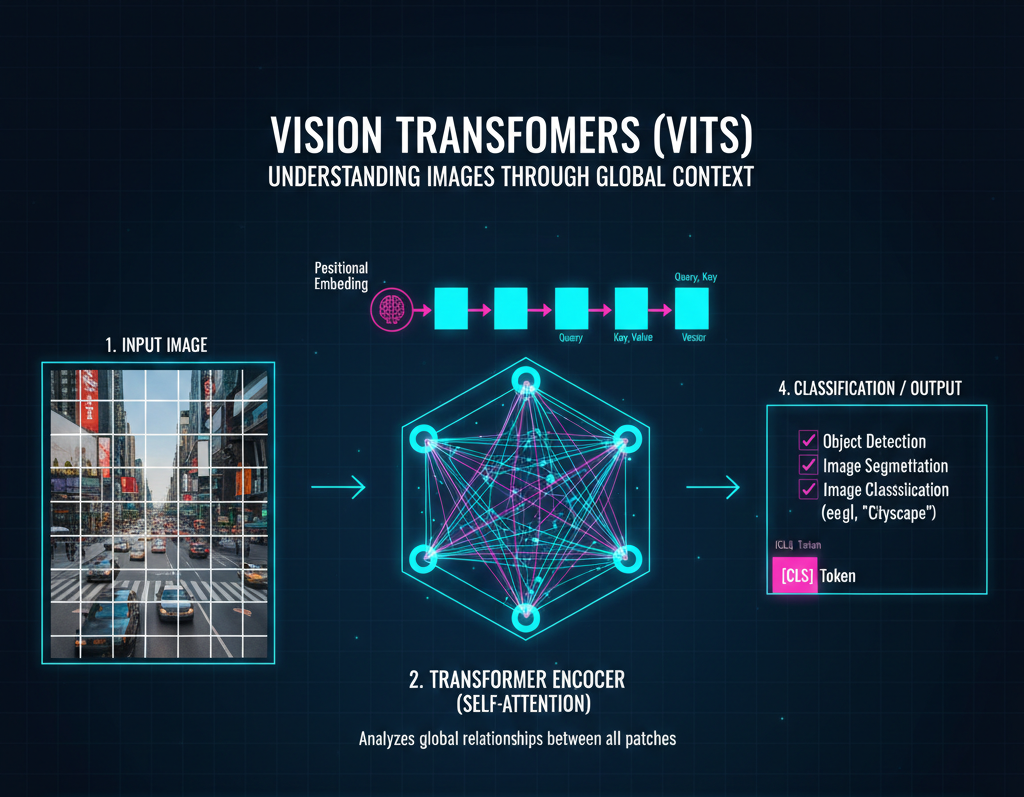
The modern frontier of CV. Adapted from the Transformer architecture used in LLMs, ViTs treat an image as a sequence of "patches." This allows the model to understand global context and long-range dependencies across an entire image.
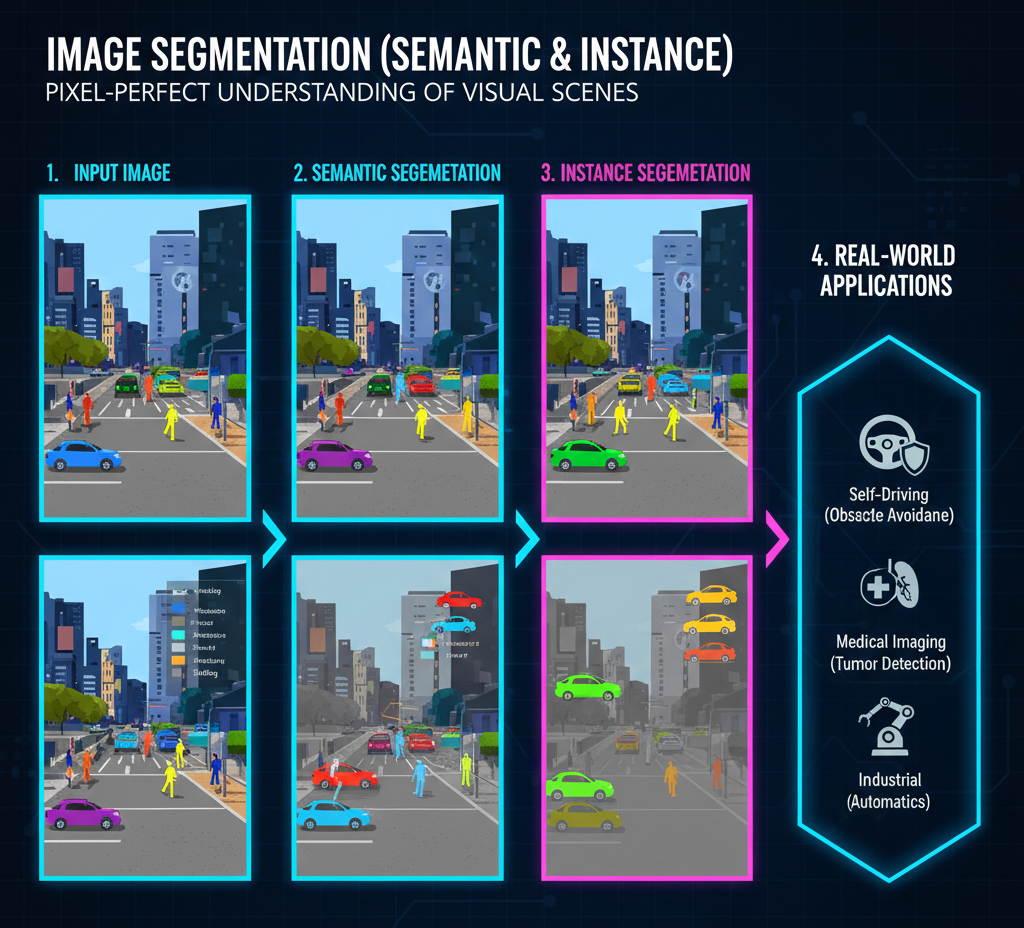
The technology for pixel-level understanding. Unlike simple classification, segmentation labels every single pixel. Semantic Segmentation identifies categories (e.g., "road"), while Instance Segmentation identifies individual objects (e.g., "Car #1" vs "Car #2").
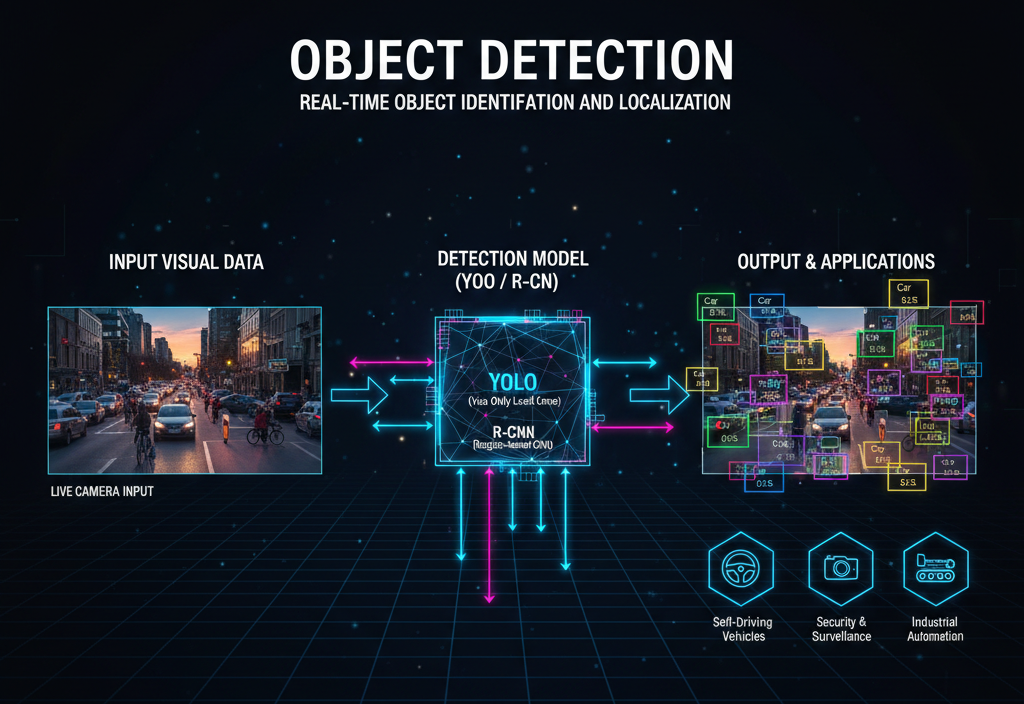
The ability to identify and locate multiple objects within a single frame. It combines classification with localization, typically by drawing "Bounding Boxes" around detected items like pedestrians, traffic lights, or obstacles.