
☰
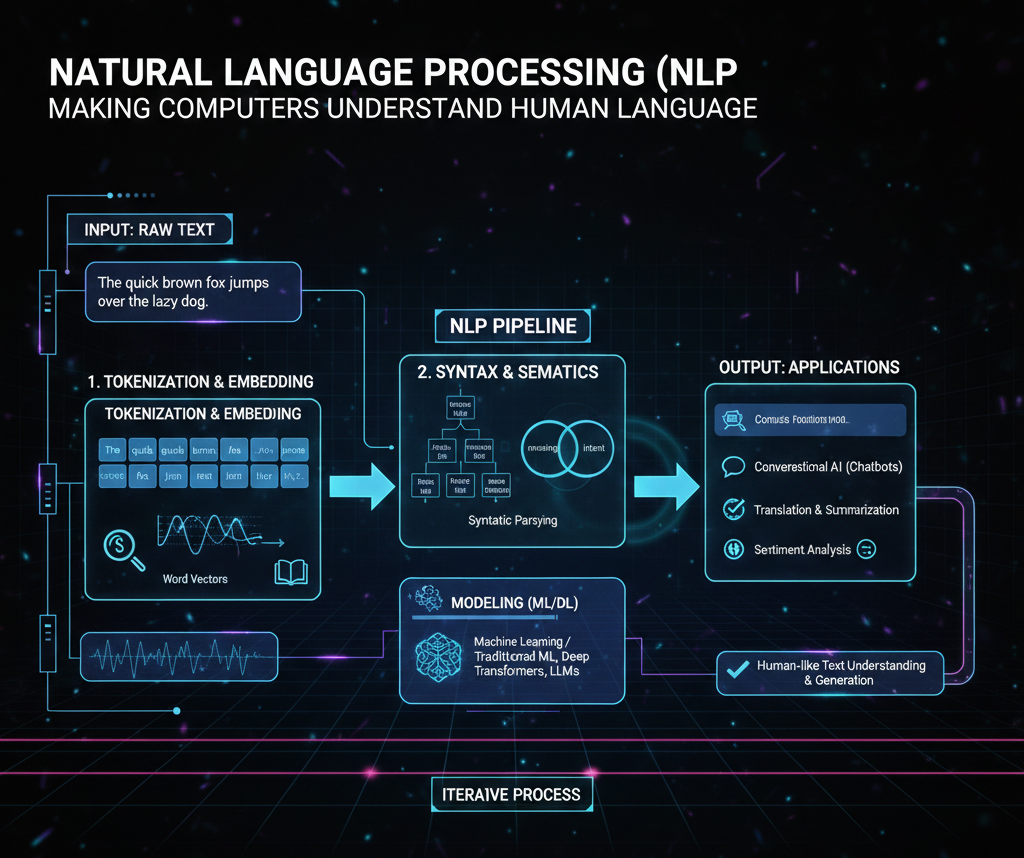
Natural Language Processing (NLP) has evolved from simple text analysis into "Natural Language Understanding and Reasoning." No longer limited to matching keywords, modern NLP leverages Large Language Models (LLMs) to grasp context, nuance, and intent across hundreds of languages and dialects.
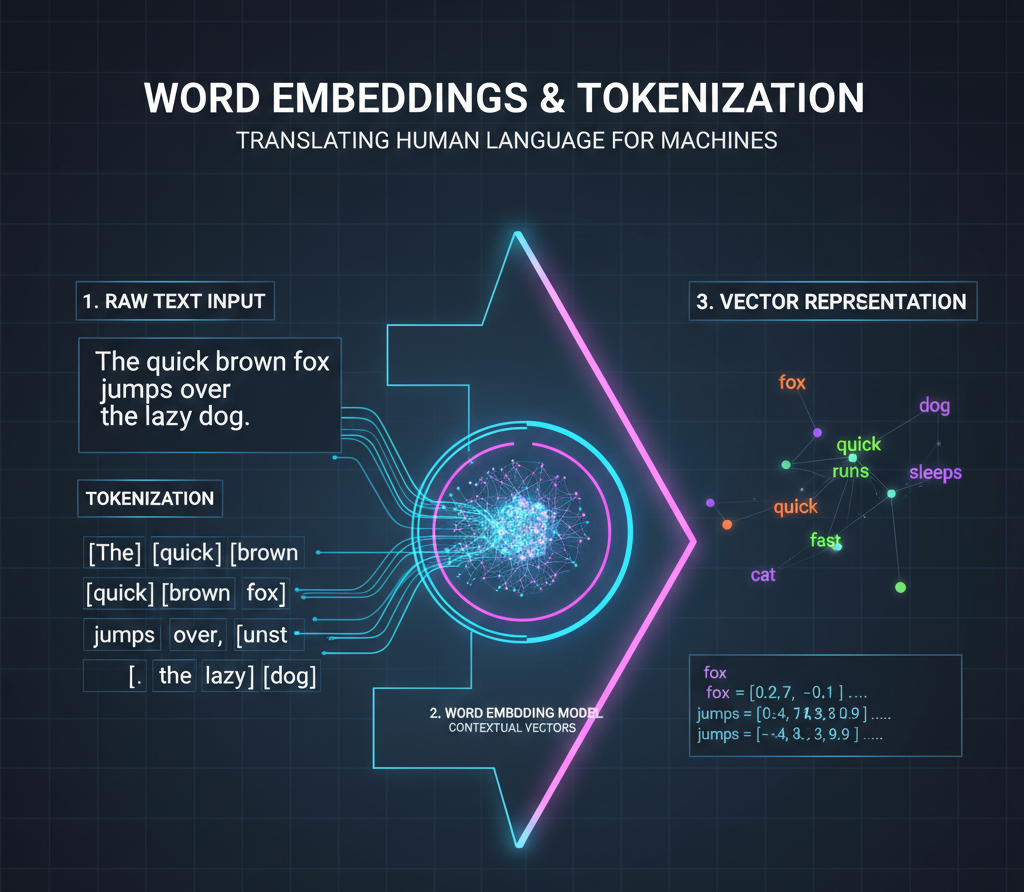
The bridge between human text and machine math. Tokenization breaks text into chunks, while Embeddings map those chunks into a high-dimensional vector space where words with similar meanings are mathematically positioned close to each other.
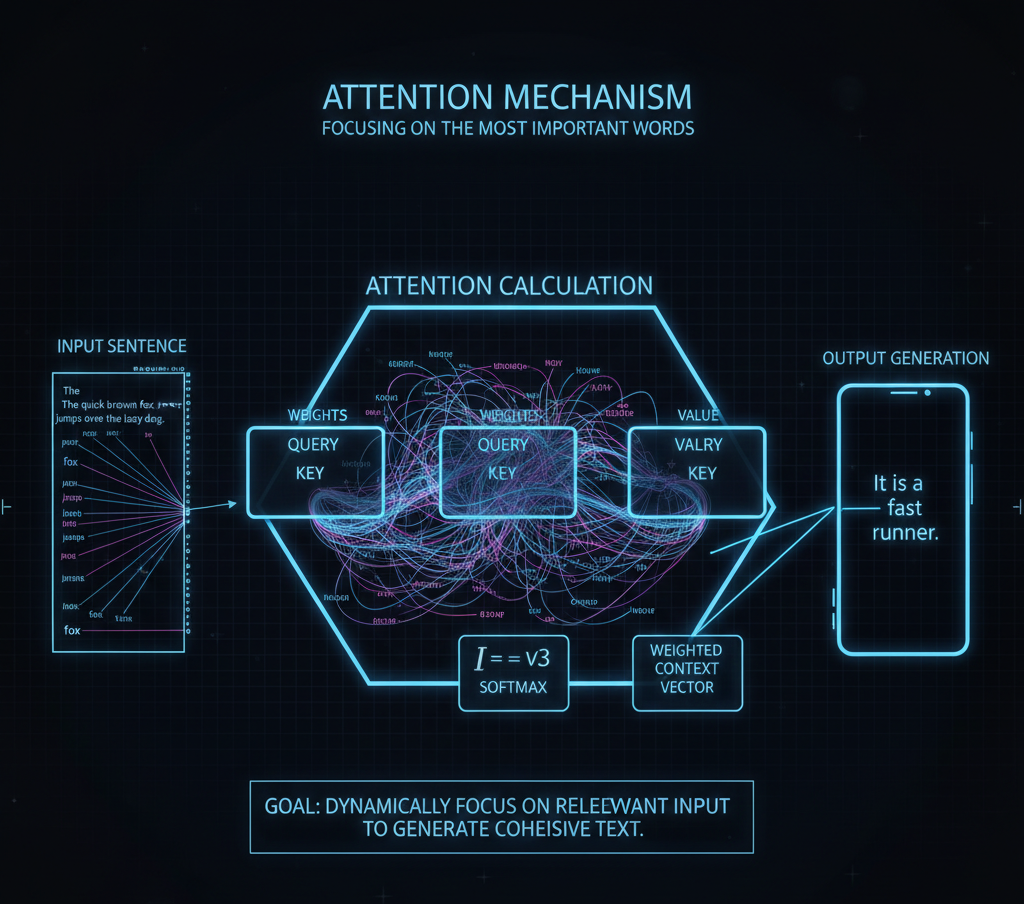
The specific mathematical process that allows a model to "focus" on relevant parts of an input sequence. It assigns different weights to different words, ensuring that when the model generates a pronoun, it "remembers" which noun it is referring to earlier in the text.
A set of techniques that allows developers to adapt massive models to specific tasks (e.g., medical or legal writing) by only updating a tiny fraction of the model's weights, making customization faster and cheaper.
