☰
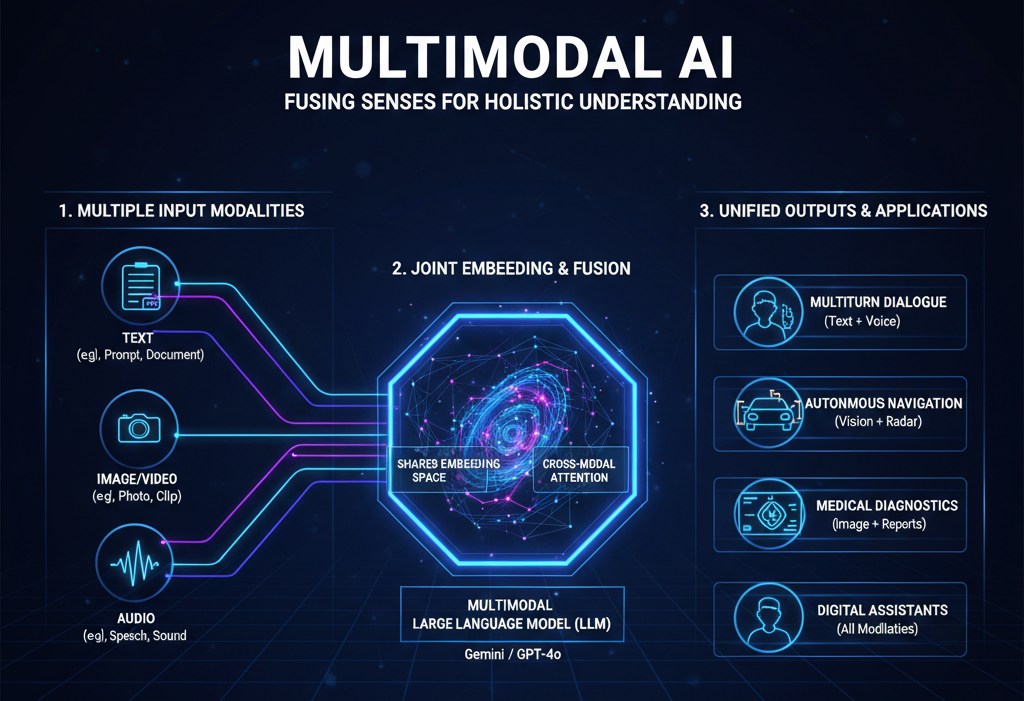
Multimodal AI refers to a class of machine learning models capable of processing, understanding, and generating information across multiple types of data, or "modalities," such as text, images, audio, and video. Unlike standard unimodal systems—which are limited to a single input type (like a text-only chatbot)—multimodal models can correlate information between different senses. For example, they can "see" a photograph and "describe" it in text, or "listen" to a video and "identify" the objects within it.
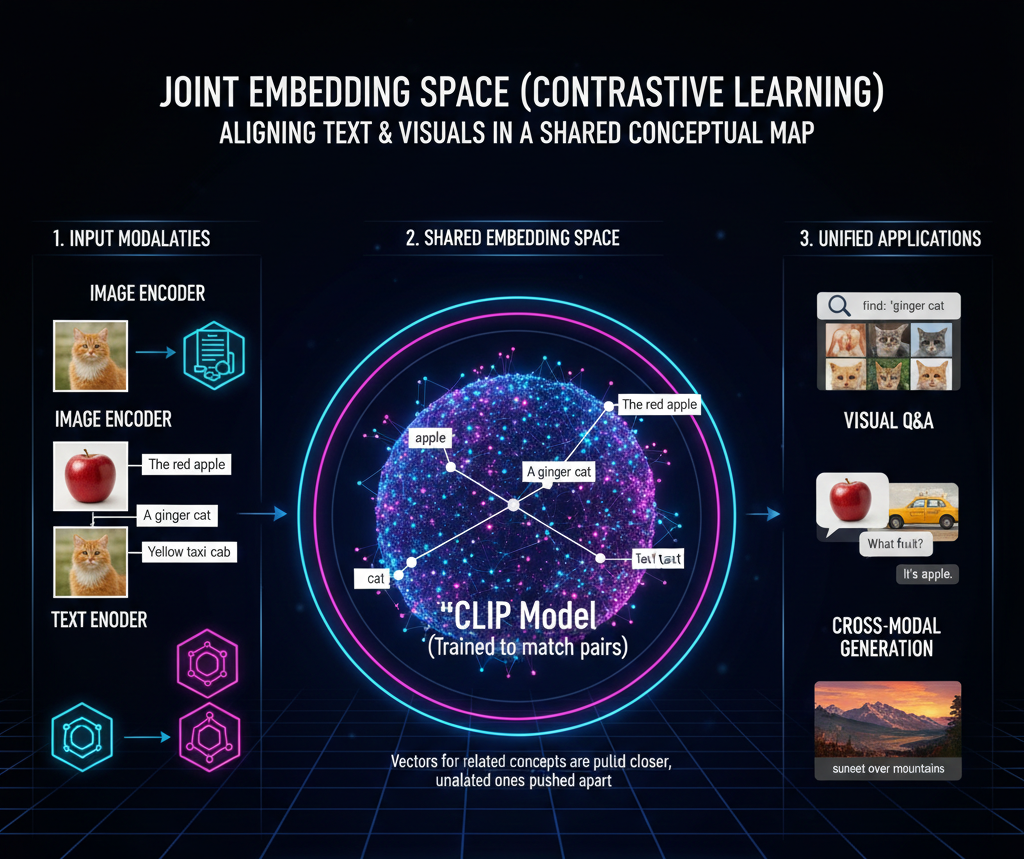
The technical core of multimodality involves mapping different data types into a joint embedding space. This allows the model to realize that the written word "apple" and an actual image of a red fruit represent the same concept. Key architectures facilitating this include CLIP (Contrastive Language-Image Pre-training) and multimodal Large Language Models. By mimicking the way humans perceive the world through multiple senses simultaneously, multimodal AI achieves a more holistic and human-like understanding of complex environments, making it essential for advanced robotics, autonomous driving, and intuitive digital assistants.
This is the most fundamental technology. It maps different modalities (like a picture of a cat and the word "cat") into the same mathematical space. It ensures the model understands that a visual object and a text description represent the same concept.
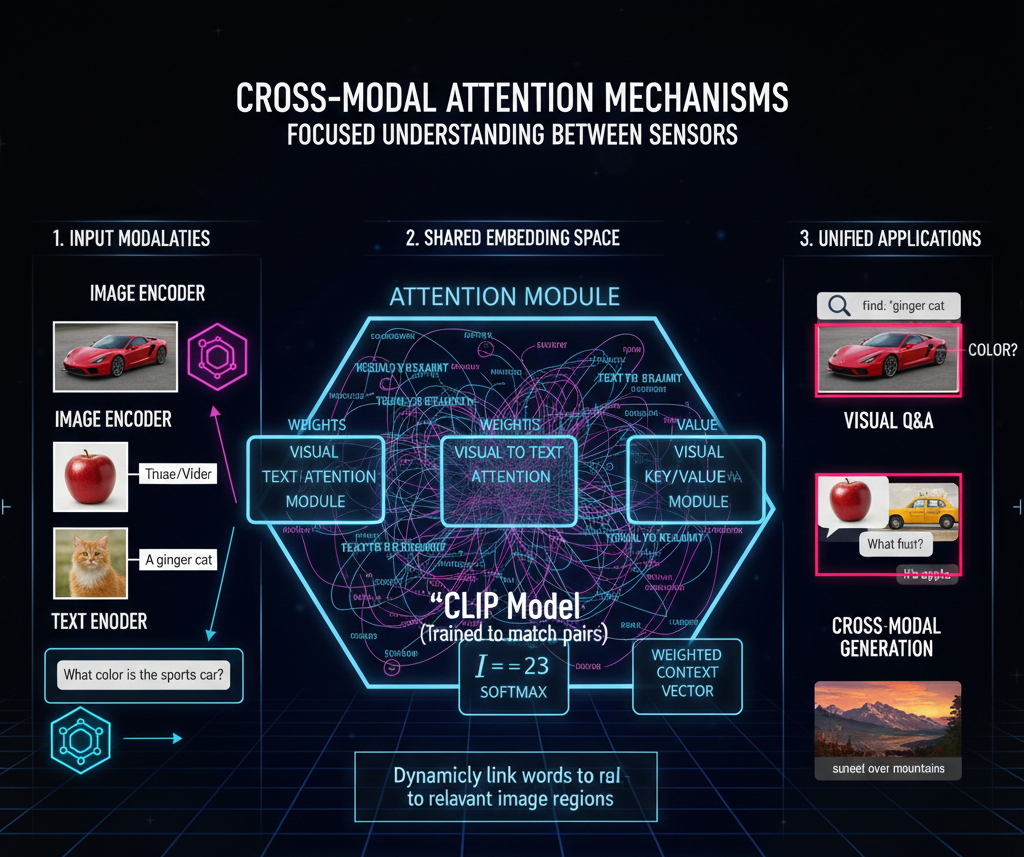
While standard attention looks at relationships within text, Cross-Attention allows the model to "look" at an image while "reading" a question about it. It dynamically weights which parts of the visual data are most relevant to specific words in the text.
To process diverse data, models use specialized "eyes" and "ears." Vision Transformers (ViTs) are used for images, while Transformer Encoders handle text. Technologies like Adapters allow these separate encoders to talk to each other without needing to retrain the entire massive model.
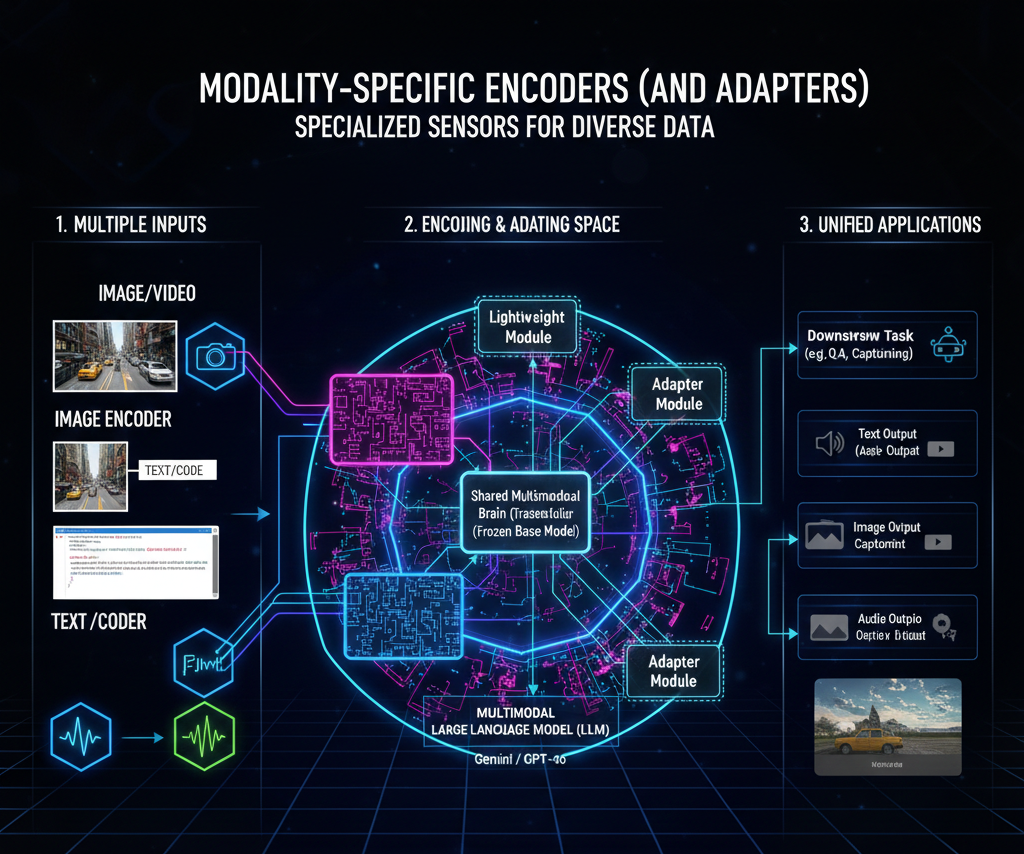
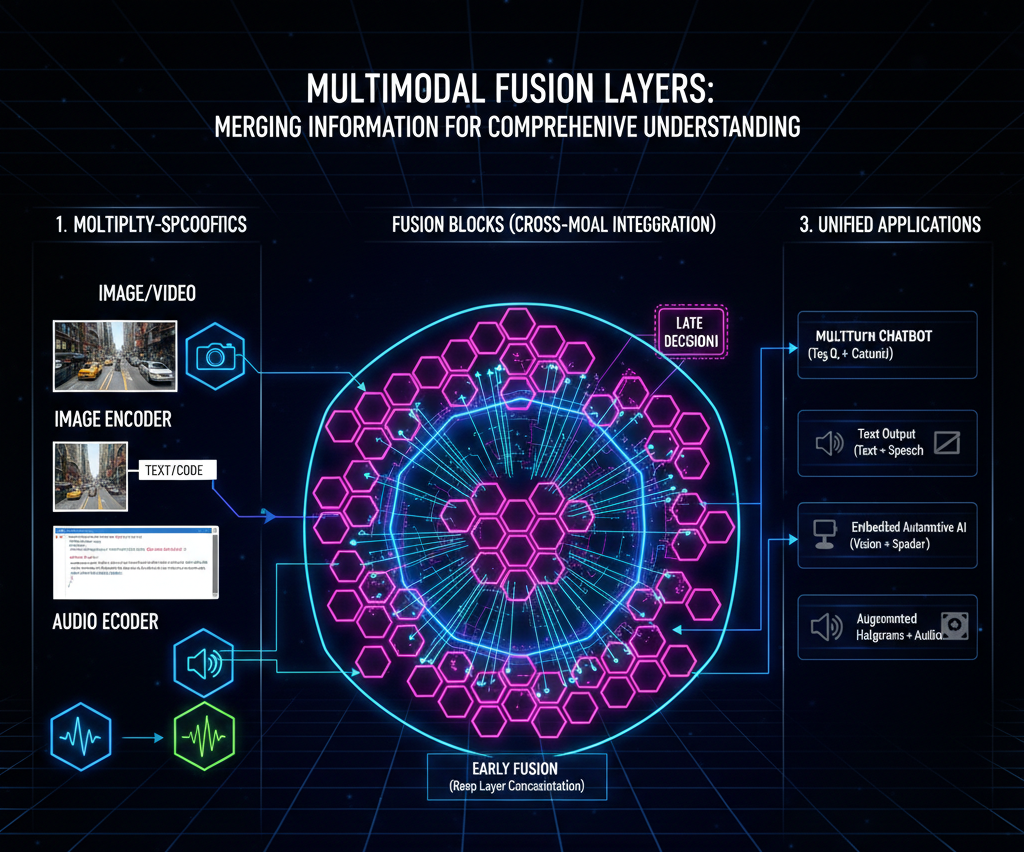
This is where the "merging" happens. Fusion technology determines how and when to combine the data streams.
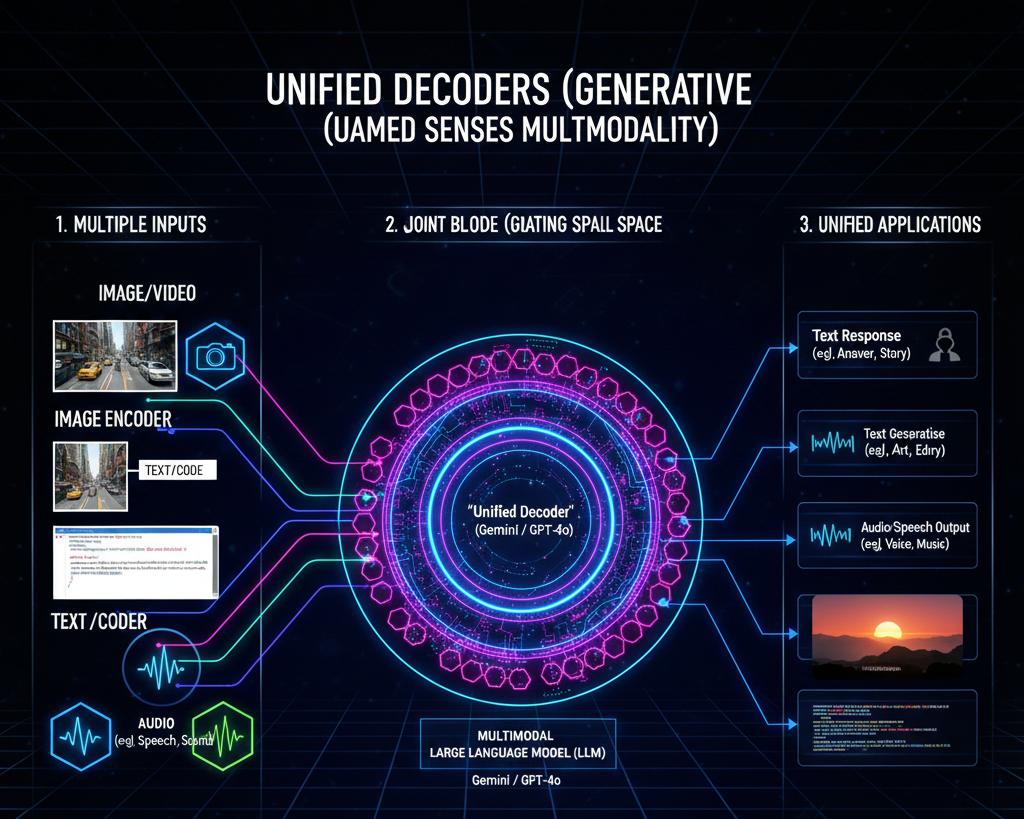
This technology allows the model to not just understand but output in any format. Instead of just replying with text, a unified decoder can decide to generate an image, a snippet of audio, or a video as the most appropriate response to a user's prompt.